FaceFusion 3.3.2 详细设置 设置(中级)
FaceFusion 在 3.3.2 更新后有了长足的发展。
它现在比以前的版本更具可配置性、
FaceFusion 3.3.2 现在比以前的版本更具可配置性,能生成满足您最复杂需求的视频。
基本上,您可以使用默认设置生成高质量的人脸合成视频。
本节将为希望生成更高级视频的用户介绍详细的设置。
请注意,某些设置可能需要更多资源,并大大增加处理时间、
这一点请务必牢记。
处理器部分
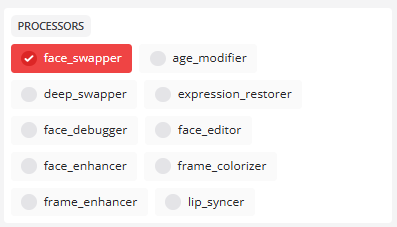
- 换脸
默认已启用,允许交换脸部。
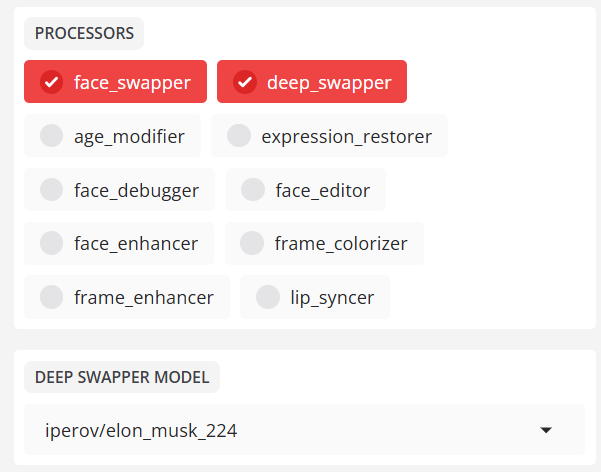
核心换脸功能可根据inswapper_128 等模型进行换脸。 - deep_swapper(深度换脸)
替代深度伪造模型(默认不启用)
默认:iperov/elon_musk_224
选择:druuzil、edel、iperov、jen、mats、rumateus
示例:--deep-swapper-model iperov/jackie_chan_224
- face_debugger (面部调试器)
用于在应用掩码时进行调试。正常运行时不需要。显示人脸关键点检测结果,用于调试。
- 面部增强器
用于增强扫描面部的清晰度。
增强面部各部分(眼睛、皮肤等)的细节。
模型:gfpgan_1.4使用 GFPGAN v1.4 模型来增强面部细节(眼睛、皮肤纹理等)。
混合:80与原始图像的混合程度(0-100)。数值越大,增强效果越明显。
- 帧增强器
增强图像质量。阴影表现
提高视频帧的整体清晰度(超分辨率)。
模型:span_kendata_x4超分辨率模型(如 kendata 和 Real-ESRGAN)可提高图像清晰度。
Blend:80还能提高混合强度。
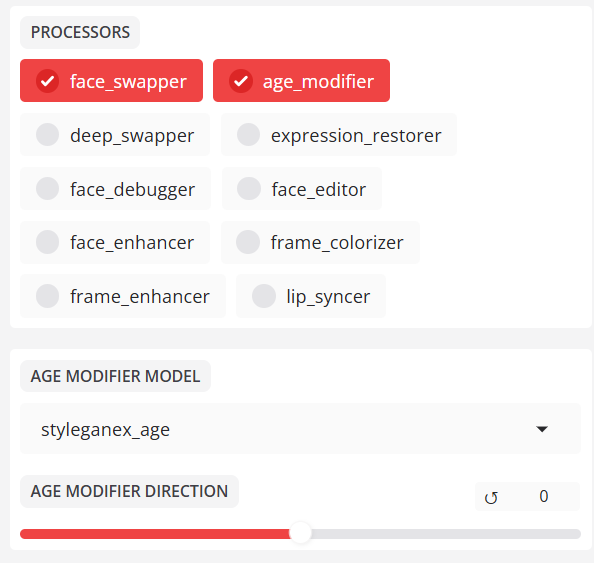
- age_modifier (年龄修正)
修改字符的年龄
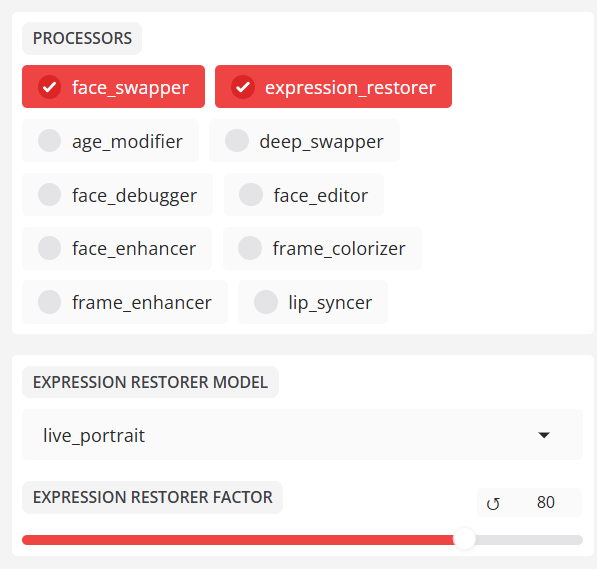
- expression_restorer(表情校正)
表情恢复器模块可修复换脸后表情呆板的问题。
expression_restorer 强度系数(0-100)。数值越大,表情越丰富,但也越容易失真
- face_editor (面部编辑器)
编辑面部特征,如眼睛大小、嘴形等(如果支持)。
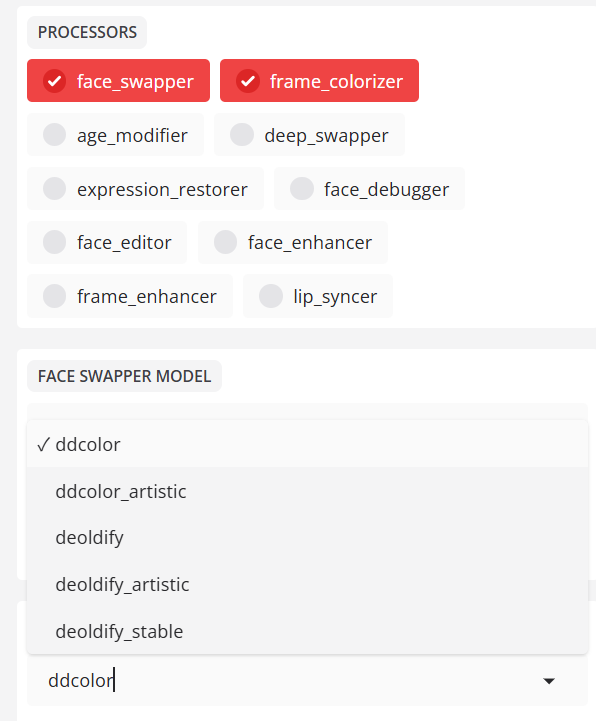
- frame_colorizer(帧着色器)
为黑白视频和图像着色。
- lip_syncer(唇部同步)
为音频驱动的视频(如话筒)提供唇语同步和面部交换功能。
换脸模式部分
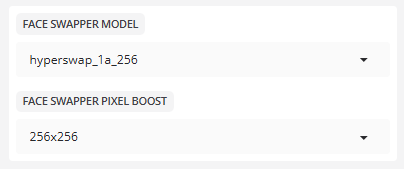
- 换脸模式
模型:新的换脸器 HyperSwap 256 模型已发布,其分辨率是 Inswapper 的两倍,据称可与 Inswapper 相媲美。
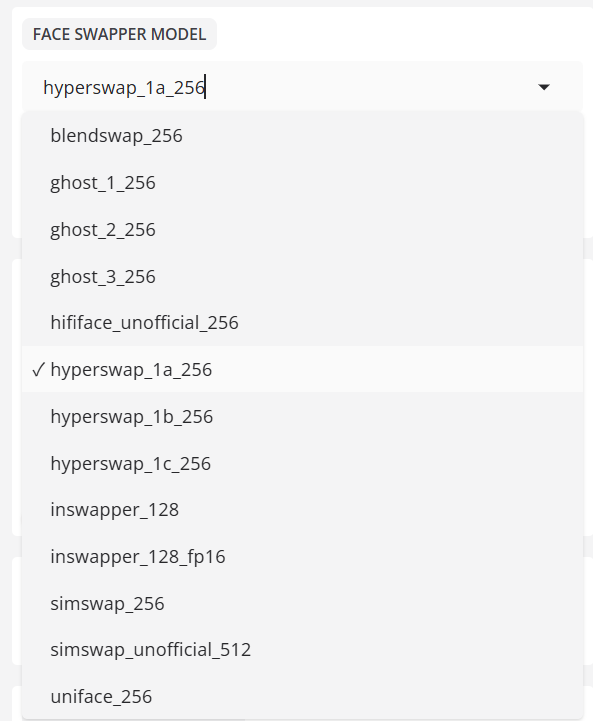
- 换脸器像素提升
像素提升:256x256
将输入图像放大至此尺寸进行处理。数值越大,图像越清晰,但也会消耗更多的视频内存。
执行部分
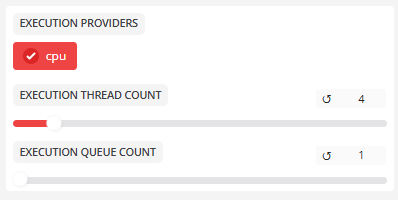
- 执行提供程序
执行提供程序:Cuda、Sensorrtcpu
首选使用的计算后端按以下顺序指定:Sensorrt > Cuda > Cpu(如果支持)。
- 执行线程数
线程数:16多线程并行操作的数量通常根据 CPU 内核数设置。
- 执行队列数
队列数:1任务队列数通常为 1。

- 下载提供商
下载提供者:Github、Huggingface
下载模型时使用的默认源地址。
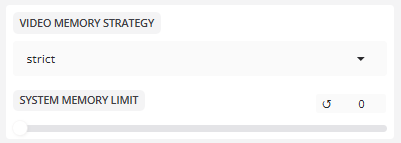
- 视频内存策略
在快速帧处理和低 VRAM 使用率之间取得平衡。
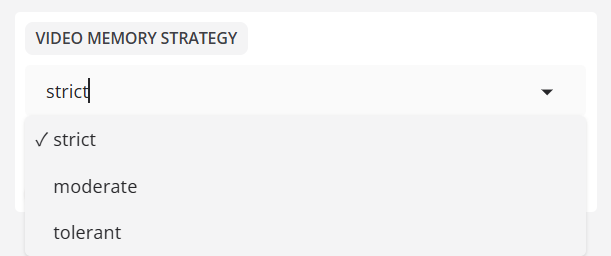
显存策略:严格、默认
容错策略tolerant意味着当显存满时,显存会自动降级。
- 系统内存限制
系统内存上限:0
内存使用上限(MB)。0 表示无限制
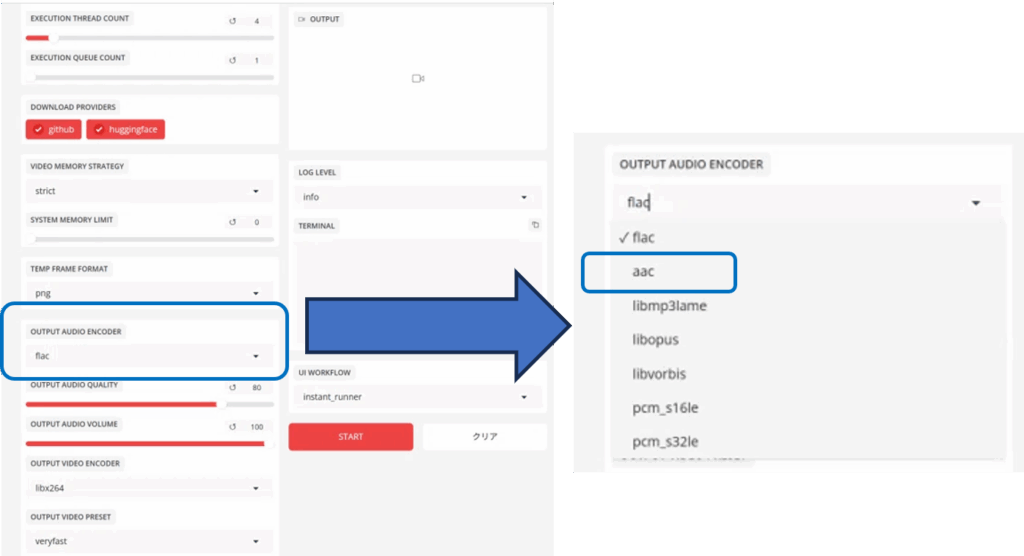
输出音频刻录机部分
指定生成视频的音频格式。默认为 “flac”。(此部分在上传目标视频后显示)。
(大多数媒体播放器使用 “aac”,因此建议切换。
面孔选择模式部分
根据目标视频中的面孔数量进行设置。

- 参考
如果视频中有多个面孔,请从紧随其后的参考图像(参考面孔)中选择要替换的面孔并执行。 - 多个
如果视频中有多个面孔,则用一个面孔(SOURCE)替换所有面孔。 - 一个
如果视频中只有一个面孔。
面罩类型部分
- 面罩类型
混合和匹配不同的面罩类型。
默认:方框 - 蒙版模糊
指定应用于方框蒙版的模糊程度。默认值:0.3

面部选择器部分
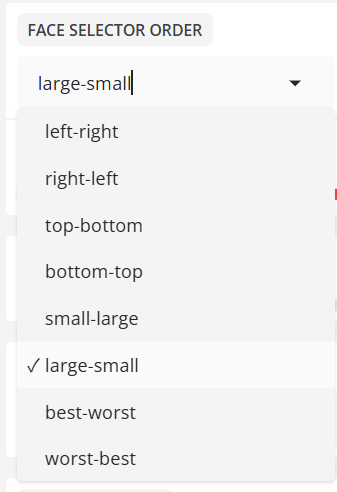
- 面孔选择器顺序
指定检测到的脸部的顺序。
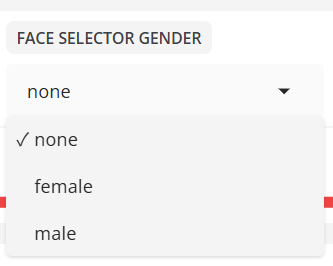
- 面孔选择器性别
根据性别过滤检测到的面孔。
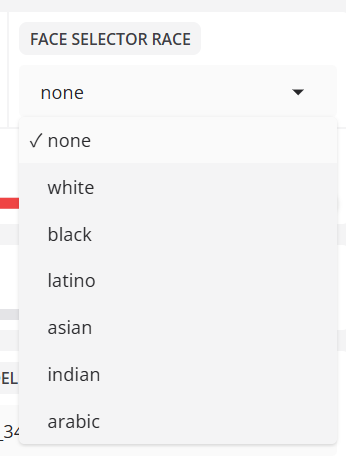
- 人脸选择器 种族
根据种族过滤检测到的人脸。
人脸遮挡器部分
- 人脸遮挡模型
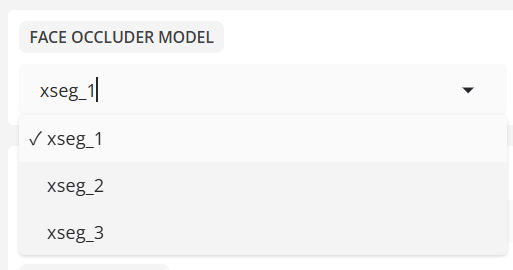
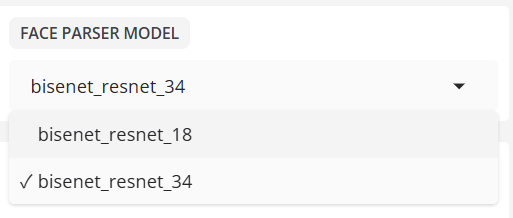
- 人脸分析器模型
选择负责区域遮挡的模型。
- 脸部蒙版顶部填充
对方框蒙版应用顶部、右侧、底部和左侧填充。
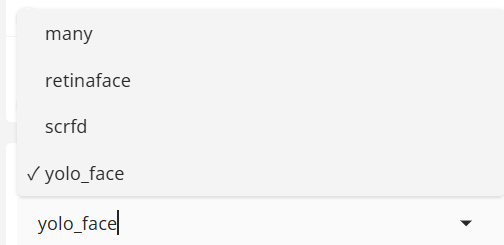
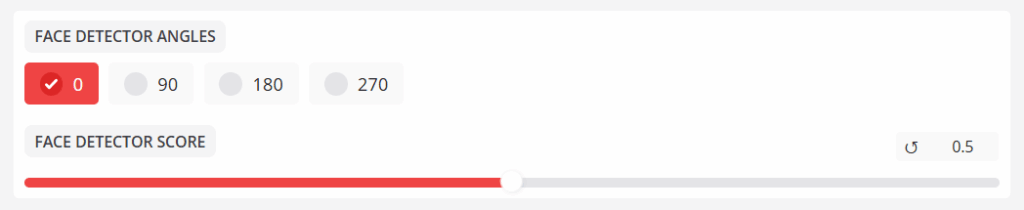
人脸检测器角度部分
- 人脸检测器角度
指定目标视频中的脸部角度是 90 度、180 度还是 270 度。 - 人脸检测器分数
ANGLES将检测到的人脸基数过滤为置信度分数。