FaceFusion 3.3.2 detaillierte Einstellungen Einstellungen (Zwischenstufe)
FaceFusion hat sich mit dem Update 3.3.2 erheblich weiterentwickelt.
Es ist jetzt noch besser konfigurierbar als in früheren Versionen,
FaceFusion 3.3.2 ist jetzt noch besser konfigurierbar als die Vorgängerversionen und kann Videos erzeugen, die auch Ihre anspruchsvollsten Anforderungen erfüllen.
Grundsätzlich können Sie mit den Standardeinstellungen qualitativ hochwertige FaceFusion-Videos erzeugen.
In diesem Abschnitt werden detaillierte Einstellungen für diejenigen beschrieben, die anspruchsvollere Videos erstellen möchten.
Bitte beachten Sie, dass einige Einstellungen mehr Ressourcen erfordern und die Verarbeitungszeit erheblich verlängern können,
Dies ist wichtig zu beachten.
Abschnitt PROCESSORS
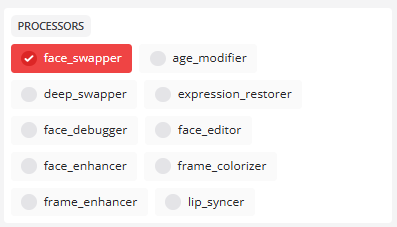
- gesicht_wechsler
Standardmäßig aktiviert, um das Vertauschen von Gesichtern zu ermöglichen.
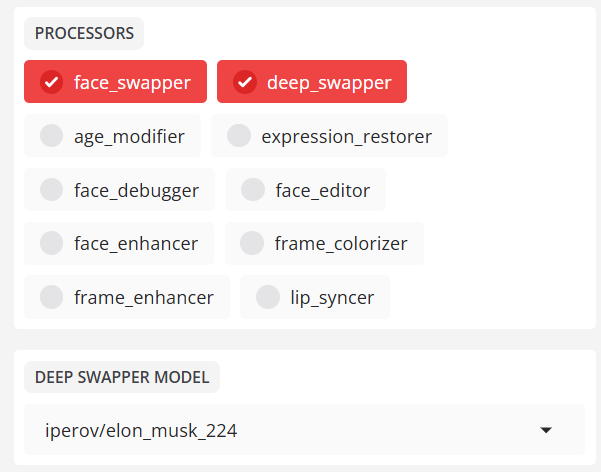
Die Kernfunktion Gesichtswechsel ermöglicht den Austausch von Gesichtern auf der Grundlage von Modellenwie inswapper_128. - deep_swapper (tiefes Tauschmodell)
Alternatives Deep-Fake-Modell (standardmäßig nicht aktiviert)
Voreinstellung:iperov/elon_musk_224
Auswahl:druuzil,edel,iperov,jen,mats,rumateus
Beispiel:--deep-swapper-model iperov/jackie_chan_224
- face_debugger (Gesichtsdebugger)
Nützlich für die Fehlersuche bei Maskenanwendungen. Für den normalen Betrieb nicht erforderlich. Zeigt die Ergebnisse der Erkennung von Gesichtspunkten zu Debugging-Zwecken an.
- face_enhancer
Wird verwendet, um die Klarheit eines überstrichenen Gesichts zu verbessern.
Verbessert die Details von Gesichtsteilen (Augen, Haut, etc.).
Modell:gfpgan_1.4Verwendet das Modell GFPGAN v1.4 zur Verbesserung der Gesichtsdetails (Augen, Hauttextur usw.).
Überblendung:80Grad der Überblendung mit dem Originalbild (0-100). Je höher der Wert, desto ausgeprägter ist die Verbesserung.
- frame_enhancer
Verbessert die Bildqualität. Schatten auf Leistung
Verbessert die allgemeine Klarheit von Videobildern (Superauflösung).
Modell:span_kendata_x4Modelle mit hoher Auflösung (wie kendata und Real-ESRGAN) verbessern die Bildschärfe.
Blend:80Verbessert auch die Intensität der Überblendung.
- age_modifier (Alterskorrektur)
Ändert das Alter der Figur
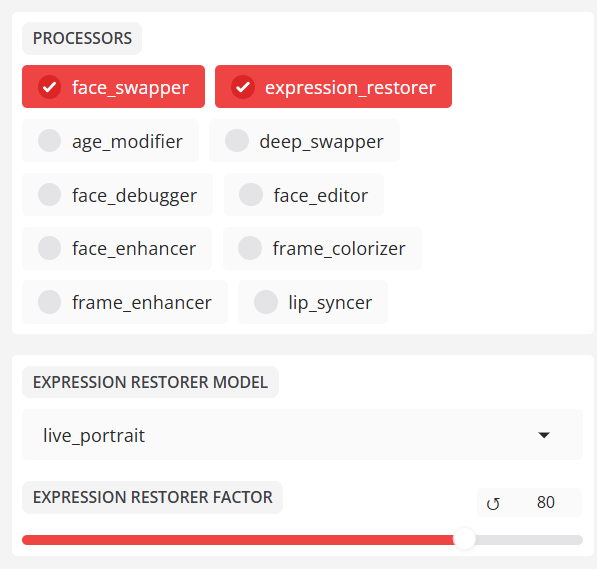
- expression_restorer (Ausdruckskorrektur)
Das Modul Expression Restorer behebt Probleme mit stumpfen Ausdrücken nach einer Gesichtsveränderung.
expression_restorer Intensitätskoeffizient (0-100). Höhere Werte sind ausdrucksstärker, aber auch anfälliger für Verzerrungen
- face_editor (Gesichtseditor)
Bearbeitet Gesichtsmerkmale wie Augengröße, Mundform usw. (sofern unterstützt).
- frame_colorizer (Bildeinfärber)
Einfärben von Schwarz-Weiß-Videos und Bildern.
- lip_syncer (Lippensynchronisation)
Lippensynchronisation, Gesichtsaustausch für audiogestützte Videos (z. B. Talking Heads).
Abschnitt FACE SWAPPER MODEL
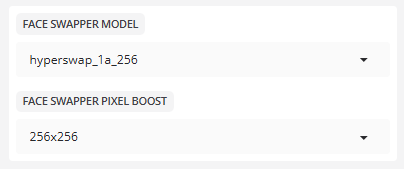
- GESICHTSTAUSCHERMODELL
MODELL: Das neue Swapper-Modell HyperSwap 256, mit doppelter Auflösung und angeblich vergleichbar mit dem Inswapper, wurde veröffentlicht.
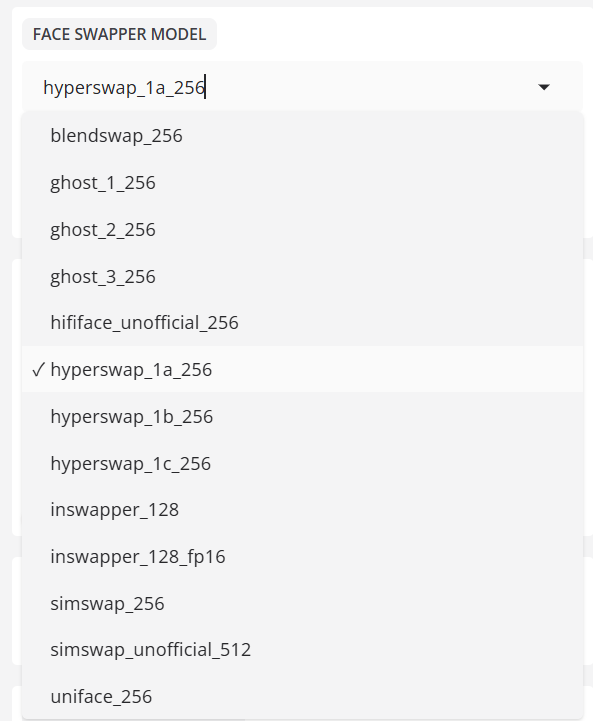
- FACE SWAPPER PIXEL BOOST
Pixelverstärkung:256x256
Vergrößert das Eingabebild für die Verarbeitung auf diese Größe. Größere Werte erzeugen schärfere Bilder, verbrauchen aber auch mehr Videospeicher.
Abschnitt EXECUTION
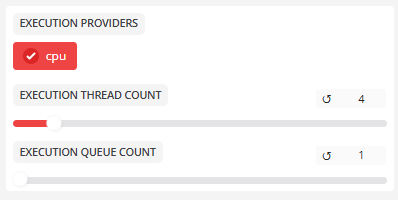
- AUSFÜHRUNGSANBIETER
Ausführungsanbieter:cuda,,sensorrtcpu
Das zu verwendende bevorzugte Berechnungs-Backend wird in folgender Reihenfolge angegeben:sensorrt > cuda > cpu(sofern unterstützt).
- ANZAHL DER AUSFÜHRUNGS-THREADS
Anzahl der Threads:16Die Anzahl der parallelen Multithreading-Operationen wird normalerweise entsprechend der Anzahl der CPU-Kerne festgelegt.
- ANZAHL DER AUSFÜHRUNGSWARTESCHLANGEN
Anzahl der Warteschlangen:1Die Anzahl der Task-Warteschlangen wird in der Regel auf 1 belassen.

- DOWNLOAD-ANBIETER
Download-Anbieter:github,huggingface
Standard-Quelladresse, die beim Herunterladen von Modellen verwendet wird.
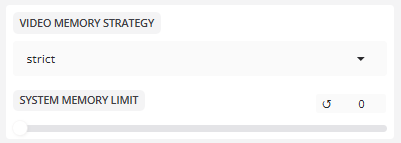
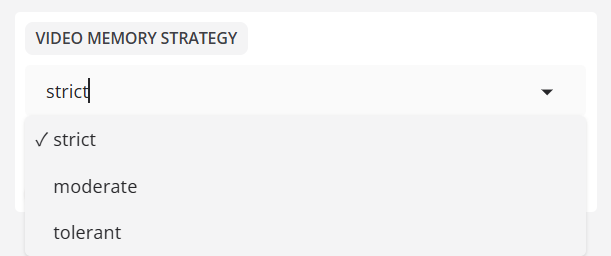
- videospeicher-Strategie
Gleichgewicht zwischen schneller Frame-Verarbeitung und geringer VRAM-Nutzung.
Videospeicher-Strategie:strikt, Standard
Die Fehlertoleranzstrategietolerantbedeutet, dass der Grafikspeicher automatisch heruntergefahren wird, wenn der Grafikspeicher voll ist.
- SYSTEM-SPEICHER-LIMIT
Grenzwert für den Systemspeicher: 0
Obere Grenze der Speichernutzung (MB). 0 bedeutet keine Begrenzung
Abschnitt OUTPUT AUDIO ENCORDER
Legt das Audioformat des erzeugten Videos fest. Standard ist „flac“. (Dieser Abschnitt wird angezeigt, nachdem das TARGET-Video hochgeladen wurde.)
(Dieser Abschnitt wird nach dem Hochladen des TARGET-Videos angezeigt.) Die meisten Mediaplayer verwenden „aac“, so dass ein Wechsel empfohlen wird.
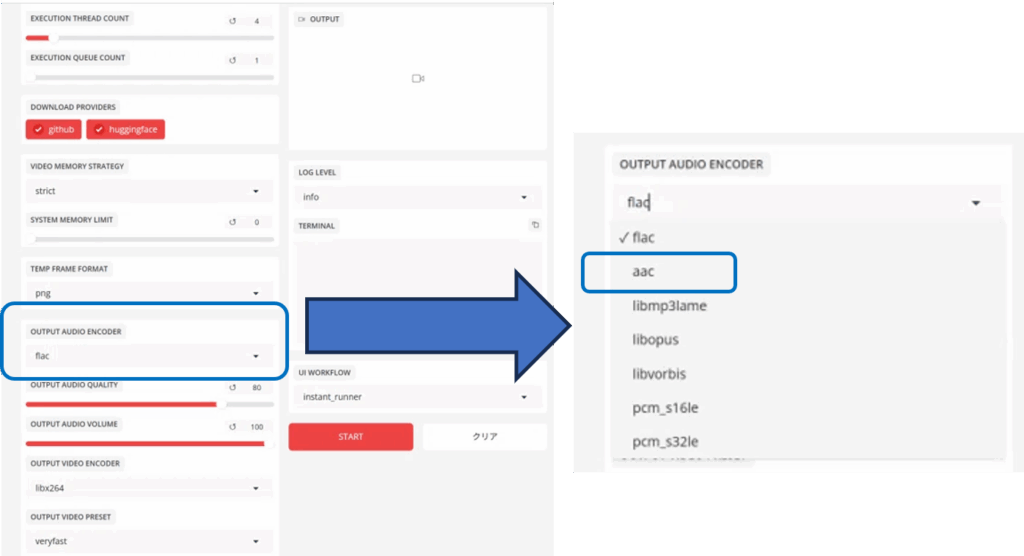
Abschnitt FACE SELECTOR MODE
Wird entsprechend der Anzahl der Gesichter im Zielvideo eingestellt.

- REFERENZ
Wenn das Video mehrere Gesichter enthält, wählen Sie das zu ersetzende Gesicht aus den Gesichtern im Referenzbild direkt darunter (REFERENZGESICHT) und führen Sie es aus. - viele
Wenn mehrere Gesichter im Video vorhanden sind, ersetzen Sie alle Gesichter durch ein Gesicht (QUELLE). - ein
Wenn es nur ein Gesicht im Video gibt.
Abschnitt FACE MASK TYPES
- GESICHTSMASKENTYPEN
Mischt und passt verschiedene Gesichtsmaskentypen an.
Standard: Kasten - GESICHTSMASKE BLUR
Gibt den Grad der Unschärfe an, der auf die Boxmaske angewendet wird. Voreinstellung: 0,3

Abschnitt FACE SELECTOR
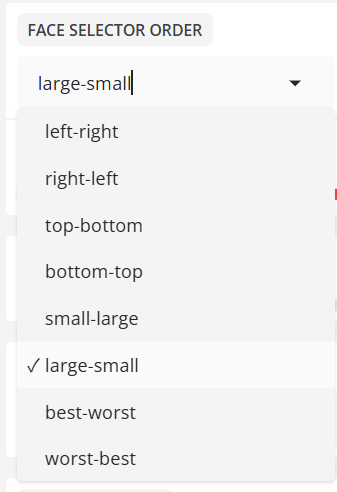
- GESICHTSAUSWAHL-REIHENFOLGE
Legt die Reihenfolge der erkannten Gesichter fest.
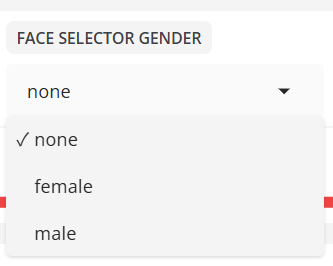
- GESICHTSWÄHLER GESCHLECHT
Filtert erkannte Gesichter nach dem Geschlecht.
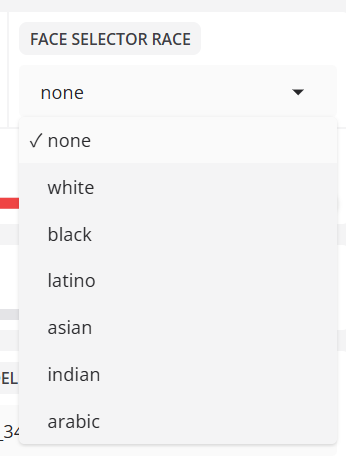
- GESICHTSSELEKTOR ETHNIE
Filtert erkannte Gesichter auf der Grundlage der Ethnie.
Abschnitt FACE MASKER
- FACE OCCLUDER MODEL
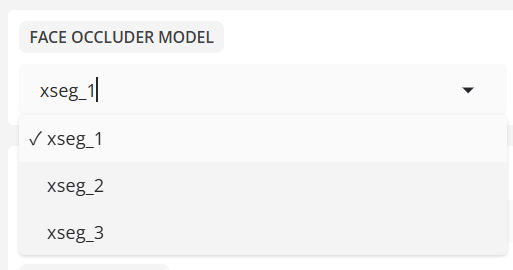
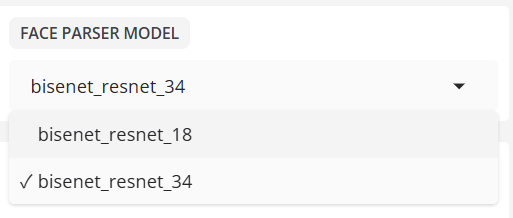
- GESICHTSPARSER-MODELL
Wählt das Modell aus, das für die Maskierung der Region verantwortlich ist.
- GESICHTSMASKE AUFFÜLLUNG OBEN
Wendet die obere, rechte, untere und linke Auffüllung auf die Boxmaske an.
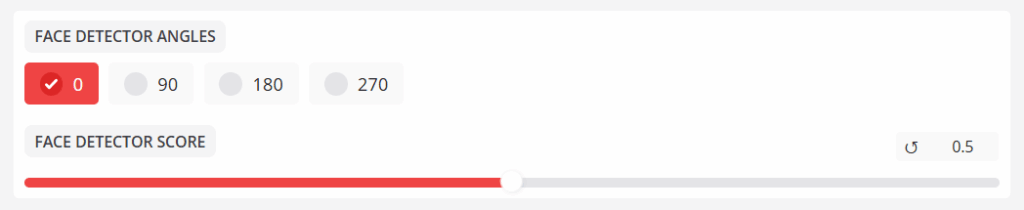
Abschnitt FACE DETECTOR ANGLES
- GESICHTSDETEKTOR-WINKEL
Gibt an, ob der Gesichtswinkel im TARGET-Video 90, 180 oder 270 Grad beträgt. - GESICHTSDETEKTOR PUNKTE
ANGLESFiltert die Basis der erkannten Gesichter in eine Vertrauensbewertung.