FaceFusion 3.3.2 세부 설정 설정(중급 수준)
FaceFusion은 3.3.2 업데이트를 통해 크게 발전했습니다.
이제 이전 버전보다 더 많은 구성이 가능합니다,
FaceFusion 3.3.2는 이제 이전 버전보다 더 많은 구성이 가능하며, 가장 정교한 요구 사항을 충족하는 동영상을 생성할 수 있습니다.
기본적으로 기본 설정으로 고품질의 얼굴 합성 동영상을 생성할 수 있습니다.
이 섹션에서는 보다 고급 동영상을 생성하려는 사용자를 위한 자세한 설정에 대해 설명합니다.
일부 설정은 더 많은 리소스가 필요하고 처리 시간이 크게 늘어날 수 있습니다,
이 점을 염두에 두어야 합니다.
프로세서 섹션
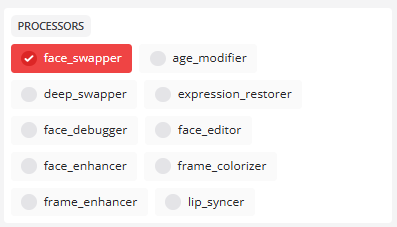
- 얼굴 스와퍼
얼굴 바꾸기를 허용하려면 기본적으로 활성화됩니다.
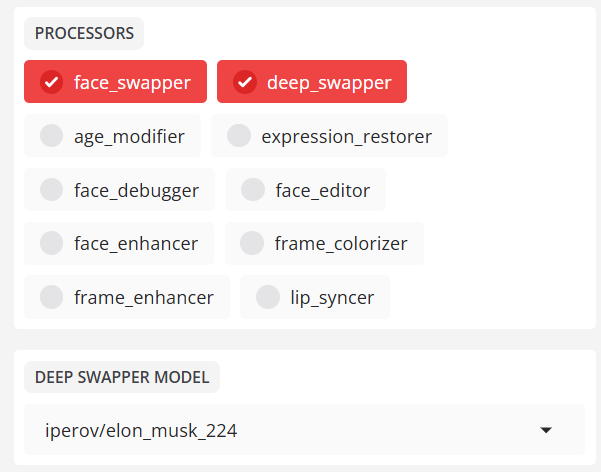
핵심 얼굴 변경 기능은inswapper_128과 같은모델을 기반으로 얼굴 교체를 제공합니다. - deep_swapper(딥 스와퍼)
대체 딥페이크 모델(기본적으로 활성화되지 않음)
기본값:iperov/elon_musk_224
선택:드루질,에델,아이페로프,젠,매트,루마테우스
예:--deep-swapper-model iperov/jackie_chan_224
- face_debugger (얼굴 디버거)
마스크 적용 중 디버깅에 유용합니다. 정상적인 작동에는 필요하지 않습니다. 디버깅 목적으로 얼굴 키포인트 감지 결과를 표시합니다.
- face_enhancer
스와이프한 얼굴의 선명도를 높이는 데 사용됩니다.
얼굴 부분(눈, 피부 등)의 디테일을 향상시킵니다.
모델:gfpgan_1.4얼굴 디테일(눈, 피부 질감 등)을 향상시키기 위해 GFPGAN v1.4 모델을 사용합니다.
블렌드: 원본 이미지와의 혼합 정도(0-100). 값이 높을수록 보정 효과가 더 뚜렷해집니다.
- 프레임 인핸서
이미지 품질을 향상시킵니다. 그림자에서 성능으로
비디오 프레임의 전반적인 선명도를 향상시킵니다(초고해상도).
모델:span_kendata_x4초고해상도 모델(예: kendata 및 Real-ESRGAN)은 이미지 선명도를 향상시킵니다.
블렌드:80또한 블렌딩 강도를 향상시킵니다.
- age_modifier(연령 보정)
캐릭터의 나이를 수정합니다
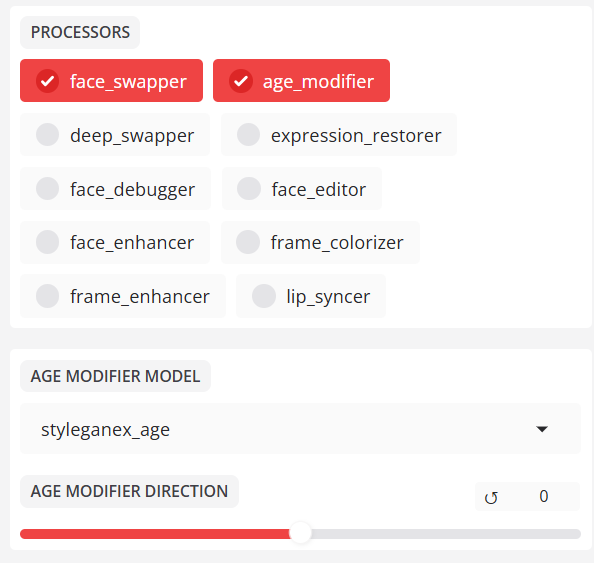
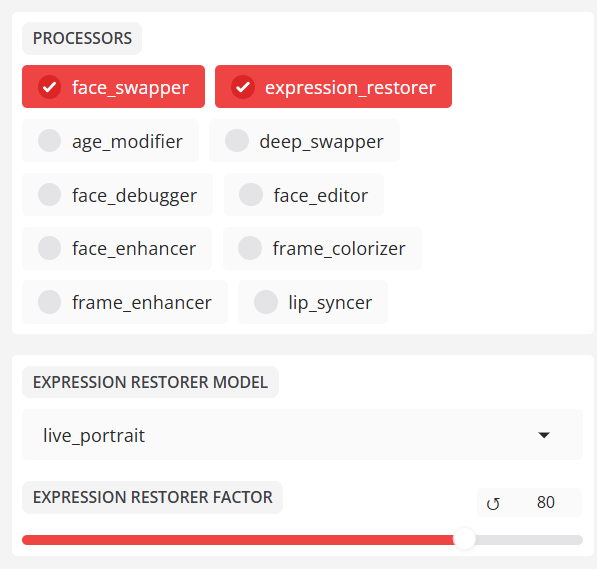
- expression_restorer (표현식 보정)
표정 복원기 모듈은 얼굴 변경 후 흐릿한 표정 문제를 해결합니다.
expression_restorer 강도 계수(0-100). 값이 높을수록 표현력이 강해지지만 왜곡이 발생하기 쉽습니다
- face_editor(얼굴 편집기)
눈 크기, 입 모양 등과 같은 얼굴 특징을 편집합니다(지원되는 경우).
- 프레임_컬러라이저(프레임 컬러라이저)
흑백 동영상과 이미지에 색상을 입힙니다.
- lip_syncer (립싱크)
립싱크, 오디오 기반 비디오(예: 말하는 머리)에 대한 얼굴 스와핑.
얼굴 스와퍼 모델 섹션
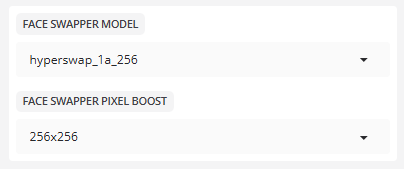
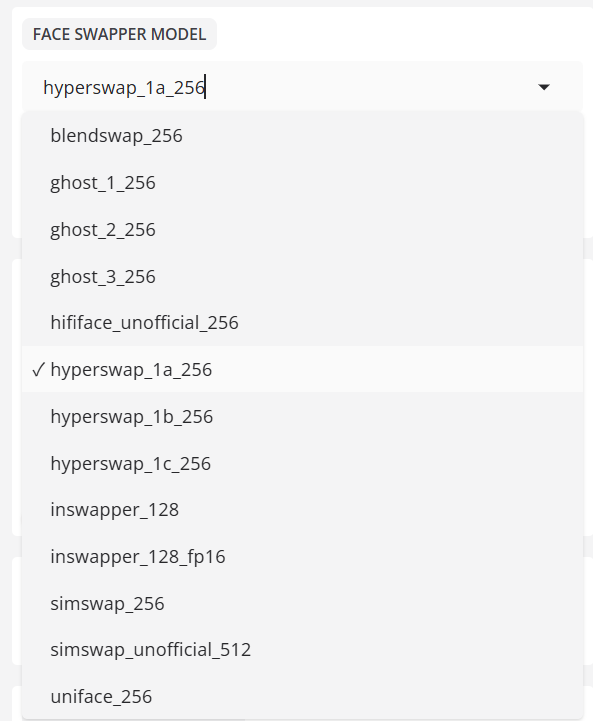
- 얼굴 스와퍼 모델
모델: 인스왑보다 해상도가 두 배 높고 인스왑에 필적할 것으로 예상되는 새로운 스왑 하이퍼스왑 256 모델이 출시되었습니다.
- 페이스 스와퍼 픽셀 부스트
픽셀 부스트:256x256
입력 이미지를 이 크기로 확대하여 처리합니다. 값이 클수록 이미지가 더 선명해지지만 비디오 메모리도 더 많이 소모됩니다.
실행 섹션
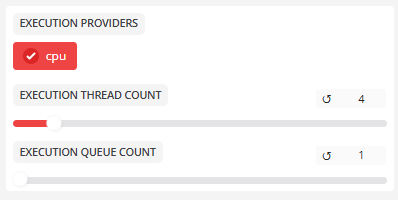
- 실행 공급자
실행 공급자:cuda,,sensorrtcpu
사용할 기본 컴퓨팅 백엔드는센서트 > 쿠다 > CPU(지원되는 경우) 순서로 지정됩니다.
- 실행 스레드 수
스레드 수:16멀티스레드 병렬 작업의 수는 일반적으로 CPU 코어 수에 따라 설정됩니다.
- 실행 대기열 수
대기열 수:1작업 대기열의 수는 일반적으로 1로 유지됩니다.

- 다운로드 공급자
다운로드 공급자:github,huggingface
모델을 다운로드할 때 사용되는 기본 소스 주소입니다.
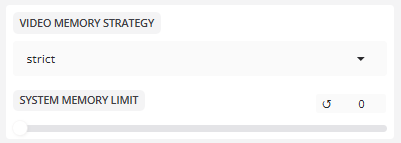
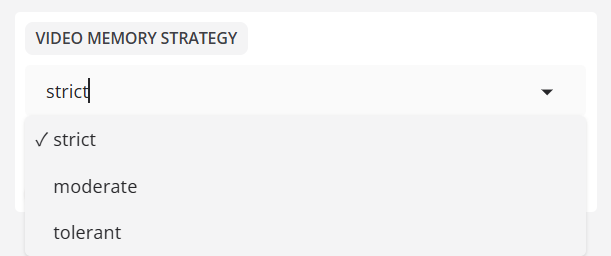
- 비디오 메모리 전략
빠른 프레임 처리와 낮은 VRAM 사용량 사이의 균형.
비디오 메모리 전략:엄격, 기본값
내결함성 정책허용은그래픽 메모리가 가득 차면 그래픽 메모리가 자동으로 다운그레이드되는 것을 의미합니다.
- 시스템 메모리 제한
시스템 메모리 제한: 0
메모리 사용량의 상한(MB)입니다. 0은 제한이 없음을 의미합니다
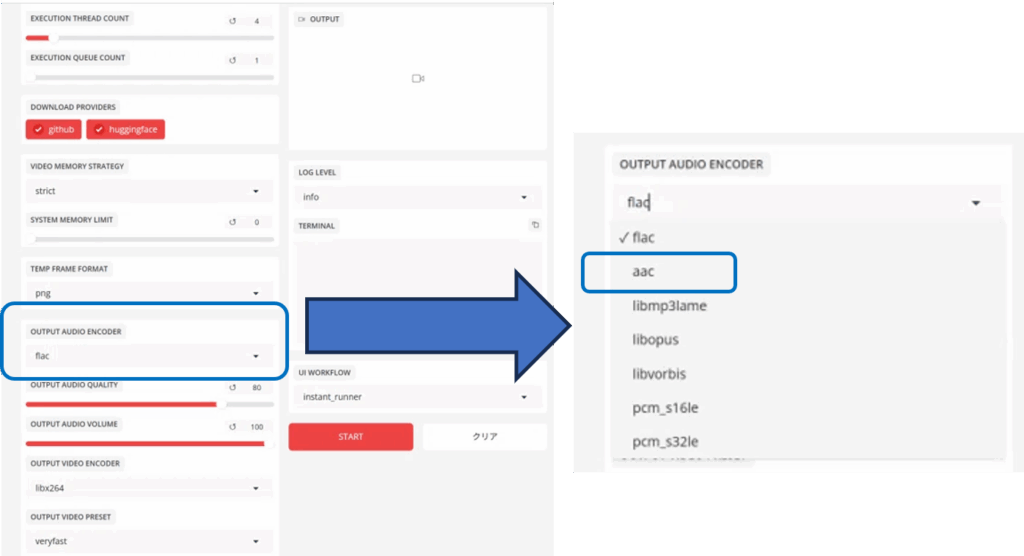
출력 오디오 인코더 섹션
생성된 비디오의 오디오 형식을 지정합니다. 기본값은 “flac”입니다. (이 섹션은 대상 비디오가 업로드된 후에 표시됩니다.)
(이 섹션은 타겟 동영상이 업로드된 후에 표시됩니다.) 대부분의 미디어 플레이어는 “aac”를 사용하므로 전환하는 것이 좋습니다.
얼굴 선택기 모드 섹션
대상 동영상의 얼굴 수에 따라 설정합니다.

- 참고
동영상에 얼굴이 여러 개 있는 경우 바로 아래 참조 이미지의 얼굴 중에서 대체할 얼굴을 선택(참조 얼굴)한 후 실행합니다. - many
동영상에 얼굴이 여러 개 있는 경우 모든 얼굴을 하나의 얼굴로 대체합니다(SOURCE). - one
동영상에 얼굴이 하나만 있는 경우.
얼굴 마스크 유형 섹션
- 얼굴 마스크 유형
서로 다른 얼굴 마스크 유형을 혼합하고 일치시킵니다.
기본값: 상자 - 얼굴 마스크 블러
박스 마스크에 적용되는 블러 정도를 지정합니다. 기본값: 0.3

얼굴 선택기 섹션
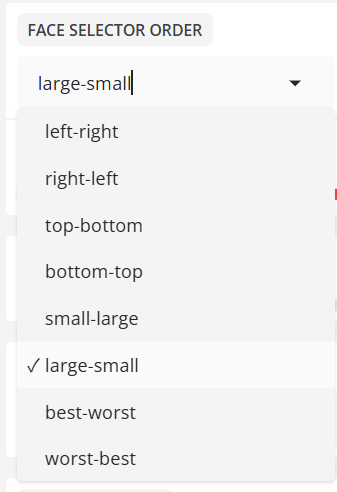
- 얼굴 선택기 순서
감지된 얼굴의 순서를 지정합니다.
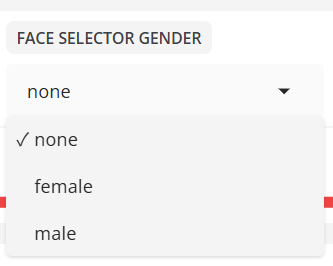
- 얼굴 선택기 성별
성별에 따라 감지된 얼굴을 필터링합니다.
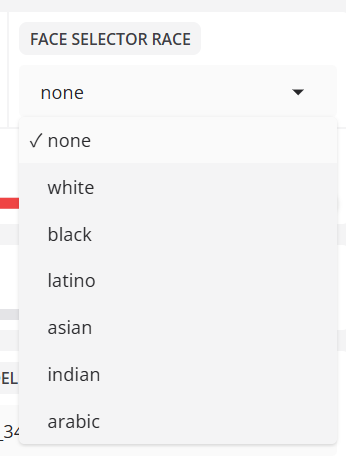
- 얼굴 선택기 인종
인종을 기준으로 감지된 얼굴을 필터링합니다.
얼굴 마스커 섹션
- 얼굴 오클루더 모델
- 얼굴 파서 모델
영역 마스킹을 담당하는 모델을 선택합니다.
- 얼굴 마스크 패딩 상단
박스 마스크에 위, 오른쪽, 아래, 왼쪽 패딩을 적용합니다.
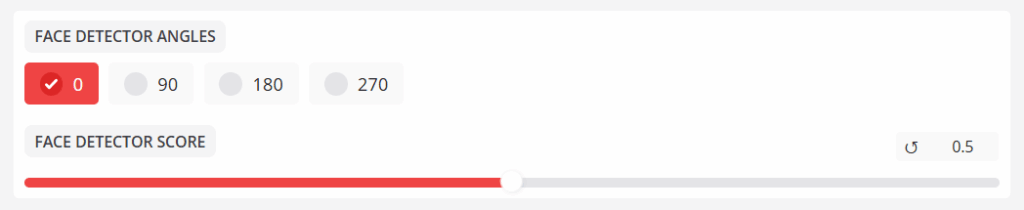
얼굴 검출기 각도 섹션
- 얼굴 검출기 각도
대상 비디오의 얼굴 각도가 90도, 180도 또는 270도인지 지정합니다. - 얼굴 검출기 점수
각도감지된 얼굴의 베이스를 신뢰도 점수로 필터링합니다.